



Рассказываем, как открытое программное обеспечение TensorRT-LLM от Nvidia может улучшить производительность больших языковых моделей и что это значит для искусственного интеллекта.
Прорыв в производительности с TensorRT-LLM
Nvidia утверждает, что их новое открытое программное обеспечение TensorRT-LL может значительно повысить производительность больших языковых моделей (LLM) на своих графических процессорах (GPU). По словам компании, возможности TensorRT-LL позволяют увеличить производительность H100, вычислительного GPU, в два раза при использовании GPT-J LLM с шестью миллиардами параметров. И, что важно, это улучшение производительности можно достичь без повторного обучения модели.
Инновационная техника «in-flight batching»
Особенностью TensorRT-LLM от Nvidia является инновационная техника «in-flight batching» (пакетная обработка во время выполнения). Этот метод решает динамические и разнообразные рабочие нагрузки LLM, которые могут сильно различаться по вычислительным требованиям.
Используя «in-flight batching,» TensorRT-LLM оптимизирует планирование этих рабочих нагрузок, обеспечивая максимальное использование ресурсов GPU. В результате запросы на реальное выполнение LLM на GPU Tensor Core H100 увеличивают производительность вдвое, что обеспечивает более быстрые и эффективные процессы искусственного интеллекта.
Эффективность и удобство использования
TensorRT-LLM от Nvidia интегрирует компилятор глубокого обучения с оптимизированными ядрами, пред- и пост-обработкой данных и примитивами для многих GPU и узлов, обеспечивая их более эффективное выполнение на графических процессорах компании. Дополняет эту интеграцию модульный Python API, который предоставляет удобный интерфейс разработчика для расширения возможностей как программного, так и аппаратного обеспечения, без глубоких знаний сложных языков программирования.
Революционные результаты
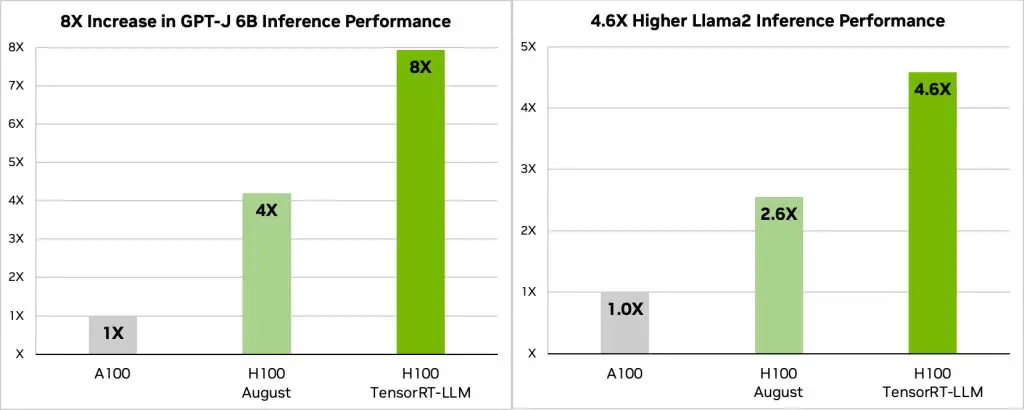
Производительность H100 от Nvidia, используемого с TensorRT-LLM, впечатляет. На архитектуре Hopper H100 GPU, совместно с TensorRT-LLM, превосходит GPU A100 в восемь раз. Кроме того, при тестировании модели Llama 2, разработанной Meta, TensorRT-LLM достиг ускорения в 4,6 раза по сравнению с GPU A100. Эти цифры подчеркивают потенциал программного обеспечения в области искусственного интеллекта и машинного обучения.
Поддержка формата FP8
Наконец, H100 GPU, при использовании TensorRT-LLM, поддерживает формат FP8. Это позволяет снизить потребление памяти без потери точности модели, что полезно для предприятий с ограниченным бюджетом и/или ограниченным пространством в центрах обработки данных и которые не могут установить достаточное количество серверов для настройки своих LLM.
Заключение
TensorRT-LLM от Nvidia — это инновационное решение, спроектированное для повышения производительности языковых моделей. Благодаря методу «in-flight batching» и другим оптимизациям, оно обеспечивает значительное увеличение скорости выполнения LLM на GPU H100. Эти разработки существенно меняют парадигму в области искусственного интеллекта и обещают улучшить производительность в задачах машинного обучения.

 для процессора в 2025 году: рейтинг лучших СВО")
